Latest update Microsoft DP-203 dumps with PDF and VCE from Lead4pass

leads4pass has just released the latest Microsoft DP-203 exam dumps! Moreover, leads4pass provides two types of DP-203 dumps-DP-203 VCE dumps and DP-203 PDF dumps.
Both VCE and PDF contain the latest DP-203 exam questions, which will help you easily pass the Microsoft DP-203 exams. ! Now, get the latest DP-203 dumps in VCE and PDF from leads4pass — https://www.leads4pass.com/dp-203.html (253 Q&A)
Read a portion of the Microsoft DP-203 exam questions and answers online
| Number of exam questions | Exam name | Exam code | Last update |
| 15 | Data Engineering on Microsoft Azure | DP-203 | DP-203 dumps |
Question 1:
You have an Azure Stream Analytics query. The query returns a result set that contains 10,000 distinct values for a column named clusterID.
You monitor the Stream Analytics job and discover high latency. You need to reduce the latency.
Which two actions should you perform? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. Add a pass-through query.
B. Add a temporal analytic function.
C. Scale out the query by using PARTITION BY.
D. Convert the query to a reference query.
E. Increase the number of streaming units.
Correct Answer: CE
C: Scaling a Stream Analytics job takes advantage of partitions in the input or output.
Partitioning lets you divide data into subsets based on a partition key. A process that consumes the data (such as a Streaming Analytics job) can consume and write different partitions in parallel, which increases throughput.
E: Streaming Units (SUs) represent the computing resources that are allocated to execute a Stream Analytics job. The higher the number of SUs, the more CPU and memory resources are allocated for your job. This capacity lets you focus
on the query logic and abstracts the need to manage the hardware to run your Stream Analytics job in a timely manner.
References: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-parallelization https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-streaming-unitconsumption
Question 2:
HOTSPOT
You need to design a data ingestion and storage solution for the Twitter feeds. The solution must meet the customer sentiment analytics requirements.
What should you include in the solution To answer, select the appropriate options in the answer area
NOTE Each correct selection b worth one point.
Hot Area:

Correct Answer:

Box 1: Configure Event Hubs partitions
Scenario: Maximize the throughput of ingesting Twitter feeds from Event Hubs to Azure Storage without purchasing additional throughput or capacity units.
Event Hubs is designed to help with the processing of large volumes of events. Event Hubs’ throughput is scaled by using partitions and throughput-unit allocations.
Event Hubs traffic is controlled by TUs (standard tier). Auto-inflate enables you to start small with the minimum required TUs you choose. The feature then scales automatically to the maximum limit of TUs you need, depending on the increase
in your traffic.
Box 2: An Azure Data Lake Storage Gen2 account
Scenario: Ensure that the data store supports Azure AD-based access control down to the object level.
Azure Data Lake Storage Gen2 implements an access control model that supports both Azure role-based access control (Azure RBAC) and POSIX-like access control lists (ACLs).
Question 3:
You have two fact tables named Flight and Weather. Queries targeting the tables will be based on the join between the following columns.
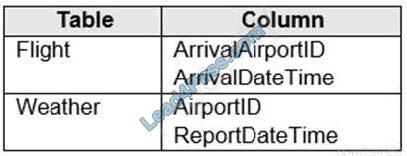
You need to recommend a solution that maximizes query performance. What should you include in the recommendation?
A. In the tables use a hash distribution of ArrivalDateTime and ReportDateTime.
B. In the tables use a hash distribution of ArrivalAirportID and AirportID.
C. In each table, create an IDENTITY column.
D. In each table, create a column as a composite of the other two columns in the table.
Correct Answer: B
Hash distribution improves query performance on large fact tables. Incorrect Answers:
A: Do not use a date column for hash distribution. All data for the same date lands in the same distribution. If several users are all filtering on the same date, then only 1 of the 60 distributions does all the processing work.
Question 4:
DRAG DROP
You have an Azure Active Directory (Azure AD) tenant that contains a security group named Group1. You have an Azure Synapse Analytics dedicated SQL pool named dw1 that contains a schema named schema1.
You need to grant Group1 read-only permissions to all the tables and views in schema1. The solution must use the principle of least privilege.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.
Select and Place:
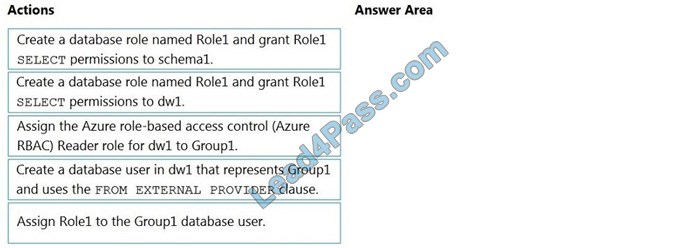
Correct Answer:

Step 1: Create a database role named Role1 and grant Role1 SELECT permissions to the schema
You need to grant Group1 read-only permissions to all the tables and views in schema1.
Place one or more database users into a database role and then assign permissions to the database role.
Step 2: Assign Rol1 to the Group database user
Step 3: Assign the Azure role-based access control (Azure RBAC) Reader role for dw1 to Group1
Reference:
https://docs.microsoft.com/en-us/azure/data-share/how-to-share-from-sql
Question 5:
You use Azure Stream Analytics to receive Twitter data from Azure Event Hubs and to output the data to an Azure Blob storage account.
You need to output the count of tweets from the last five minutes every minute.
Which windowing function should you use?
A. Sliding
B. Session
C. Tumbling
D. Hopping
Correct Answer: D
Hopping window functions hop forward in time by a fixed period. It may be easy to think of them as Tumbling windows that can overlap and be emitted more often than the window size. Events can belong to more than one Hopping window result set. To make a Hopping window the same as a Tumbling window, specify the hop size to be the same as the window size.
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-window-functions
Question 6:
DRAG DROP
You need to ensure that the Twitter feed data can be analyzed in the dedicated SQL pool. The solution must meet the customer sentiment analytic requirements.
Which three Transact-SQL DDL commands should you run in sequence? To answer, move the appropriate commands from the list of commands to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.
Select and Place:

Correct Answer:

Scenario: Allow Contoso users to use PolyBase in an Azure Synapse Analytics dedicated SQL pool to query the content of the data records that host the Twitter feeds. Data must be protected by using row-level security (RLS). The users must
be authenticated by using their own Azure AD credentials.
Box 1: CREATE EXTERNAL DATA SOURCE
External data sources are used to connect to storage accounts.
Box 2: CREATE EXTERNAL FILE FORMAT
CREATE EXTERNAL FILE FORMAT creates an external file format object that defines external data stored in Azure Blob Storage or Azure Data Lake Storage. Creating an external file format is a prerequisite for creating an external table.
Box 3: CREATE EXTERNAL TABLE AS SELECT
When used in conjunction with the CREATE TABLE AS SELECT statement, selecting from an external table imports data into a table within the SQL pool. In addition to the COPY statement, external tables are useful for loading data.
Incorrect Answers:
CREATE EXTERNAL TABLE
The CREATE EXTERNAL TABLE command creates an external table for Synapse SQL to access data stored in Azure Blob Storage or Azure Data Lake Storage.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/develop-tables-external-tables
Question 7:
You have a SQL pool in Azure Synapse.
A user reports that queries against the pool take longer than expected to complete.
You need to add monitoring to the underlying storage to help diagnose the issue.
Which two metrics should you monitor? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Cache used a percentage
B. DWU Limit
C. Snapshot Storage Size
D. Active queries
E. Cache hit percentage
Correct Answer: AE
A: Cache used is the sum of all bytes in the local SSD cache across all nodes and cache capacity is the sum of the storage capacity of the local SSD cache across all nodes.
E: Cache hits are the sum of all columnstore segments hits in the local SSD cache and cache miss is the columnstore segments misses in the local SSD cache summed across all nodes
Question 8:
HOTSPOT
You develop a dataset named DBTBL1 by using Azure Databricks.
DBTBL1 contains the following columns:
1.
SensorTypeID
2.
GeographyRegionID
3.
Year
4.
Month
5.
Day
6.
Hour
7.
Minute
8.
Temperature
9.
WindSpeed 10.Other
You need to store the data to support daily incremental load pipelines that vary for each GeographyRegionID. The solution must minimize storage costs.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
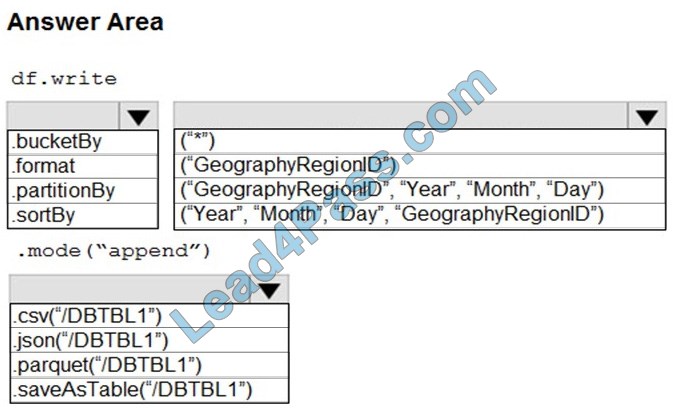
Correct Answer:
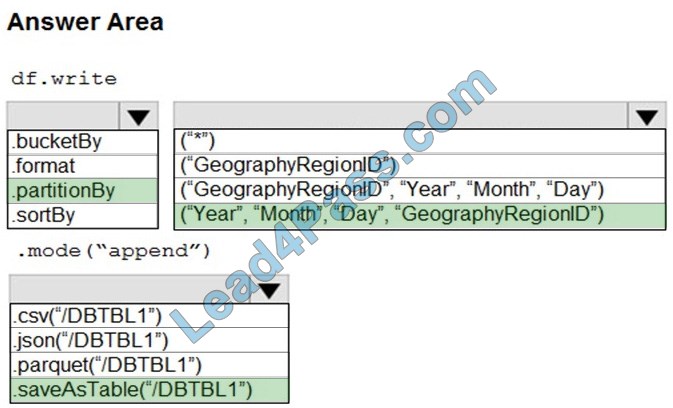
Box 1: .partitionBy
Incorrect Answers:
.format:
Method: format():
Arguments: “parquet”, “csv”, “txt”, “json”, “jdbc”, “orc”, “avro”, etc.
.bucketBy:
Method: bucketBy()
Arguments: (numBuckets, col, col…, coln)
The number of buckets and names of columns to bucket by. Uses Hive\’s bucketing scheme on a filesystem.
Box 2: (“Year”, “Month”, “Day”,”GeographyRegionID”)
Specify the columns on which to do the partition. Use the date columns followed by the GeographyRegionID column.
Box 3: .saveAsTable(“/DBTBL1”)
Method: saveAsTable()
Argument: “table_name”
The table to save to.
Reference:
https://www.oreilly.com/library/view/learning-spark-2nd/9781492050032/ch04.html
https://docs.microsoft.com/en-us/azure/databricks/delta/delta-batch
Question 9:
You have an Azure Synapse Analytics Apache Spark pool named Pool1.
You plan to load JSON files from an Azure Data Lake Storage Gen2 container into the tables in Pool1. The structure and data types vary by file.
You need to load the files into the tables. The solution must maintain the source data types.
What should you do?
A. Use a Get Metadata activity in Azure Data Factory.
B. Use a Conditional Split transformation in an Azure Synapse data flow.
C. Load the data by using the OPEHROwset Transact-SQL command in an Azure Synapse Anarytics serverless SQL pool.
D. Load the data by using PySpark.
Correct Answer: C
Serverless SQL pool can automatically synchronize metadata from Apache Spark. A serverless SQL pool database will be created for each database existing in serverless Apache Spark pools.
Serverless SQL pool enables you to query data in your data lake. It offers a T-SQL query surface area that accommodates semi-structured and unstructured data queries. To support a smooth experience for in place querying of data that\’s
located in Azure Storage files, serverless SQL pool uses the OPENROWSET function with additional capabilities.
The easiest way to see to the content of your JSON file is to provide the file URL to the OPENROWSET function, specify csv FORMAT.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/query-json-files
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/query-data-storage
Question 10:
You have an Azure Data Lake Storage account that contains a staging zone.
You need to design a daily process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics.
Solution: You use an Azure Data Factory schedule trigger to execute a pipeline that executes mapping data Flow, and then inserts the data info the data warehouse.
Does this meet the goal?
A. Yes
B. No
Correct Answer: B
If you need to transform data in a way that is not supported by Data Factory, you can create a custom activity, not a mapping flow,5 with your own data processing logic and use the activity in the pipeline. You can create a custom activity to run R scripts on your HDInsight cluster with R installed.
Reference: https://docs.microsoft.com/en-US/azure/data-factory/transform-data
Question 11:
HOTSPOT
You have an Azure Synapse Analytics dedicated SQL pool named Pool1 and an Azure Data Lake Storage Gen2 account named Account 1.
You plan to access the files in Accoun1l by using an external table.
You need to create a data source in Pool1 that you can reference when you create the external table.
How should you complete the Transact-SQL statement? To answer, select the appropriate options in the answer area.
NOTE Each coned selection is worth one point.
Hot Area:
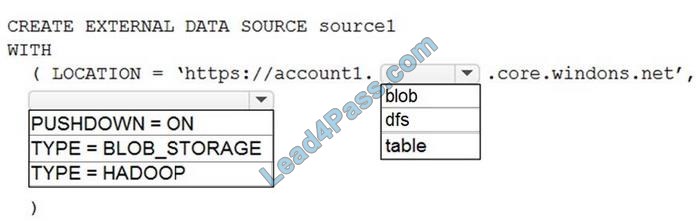
Correct Answer:

Box 1: blob The following example creates an external data source for Azure Data Lake Gen2 CREATE EXTERNAL DATA SOURCE YellowTaxi WITH ( LOCATION = \’https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/\’, TYPE = HADOOP)
Box 2: HADOOP
Question 12:
DRAG DROP
You need to create an Azure Data Factory pipeline to process data for the following three departments at your company: Ecommerce, retail, and wholesale. The solution must ensure that data can also be processed for the entire company.
How should you complete the Data Factory data flow script? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or
scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
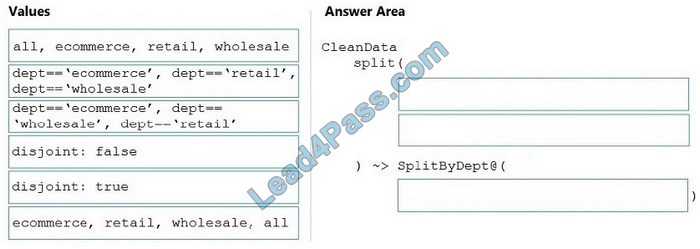
Correct Answer:

The conditional split transformation routes data rows to different streams based on matching conditions. The conditional split transformation is similar to a CASE decision structure in a programming language. The transformation evaluates expressions, and based on the results, directs the data row to the specified stream.

Box 1: dept==\’ecommerce\’, dept==\’retail\’, dept==\’wholesale\’ First we put the condition. The order must match the stream labeling we define in Box 3.
Syntax:
split(
disjoint: {true | false}
) ~> @(stream1, stream2, …, )
Box 2: discount: false
disjoint is false because the data goes to the first matching condition. All remaining rows matching the third condition go to output stream all.
Box 3: eCommerce, retail, wholesale, all
Label the streams
Question 13:
HOTSPOT
You have two Azure Storage accounts named Storage1 and Storage2. Each account holds one container and has the hierarchical namespace enabled. The system has files that contain data stored in the Apache Parquet format.
You need to copy folders and files from Storage1 to Storage2 by using a Data Factory copy activity. The solution must meet the following requirements:
1.
No transformations must be performed.
2.
The original folder structure must be retained.
3.
Minimize the time required to perform the copy activity.
How should you configure the copy activity? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
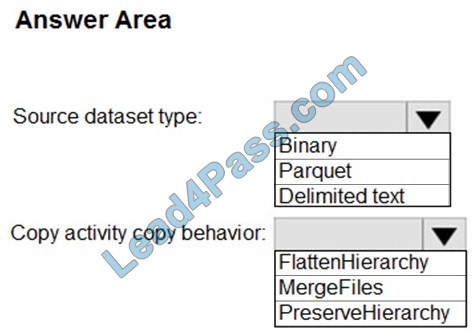
Correct Answer:

Box 1: Parquet
For Parquet datasets, the type property of the copy activity source must be set to ParquetSource.
Box 2: PreserveHierarchy
PreserveHierarchy (default): Preserves the file hierarchy in the target folder. The relative path of the source file to the source folder is identical to the relative path of the target file to the target folder.
Incorrect Answers:
FlattenHierarchy: All files from the source folder are in the first level of the target folder. The target files have autogenerated names.
MergeFiles: Merges all files from the source folder to one file. If the file name is specified, the merged file name is the specified name. Otherwise, it\’s an autogenerated file name.
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/format-parquet
https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-data-lake-storage
Question 14:
HOTSPOT
You have an Azure Synapse Analytics dedicated SQL pool that contains the users shown in the following table.
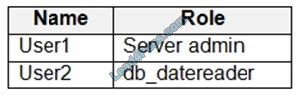
User1 executes a query on the database, and the query returns the results shown in the following exhibit.
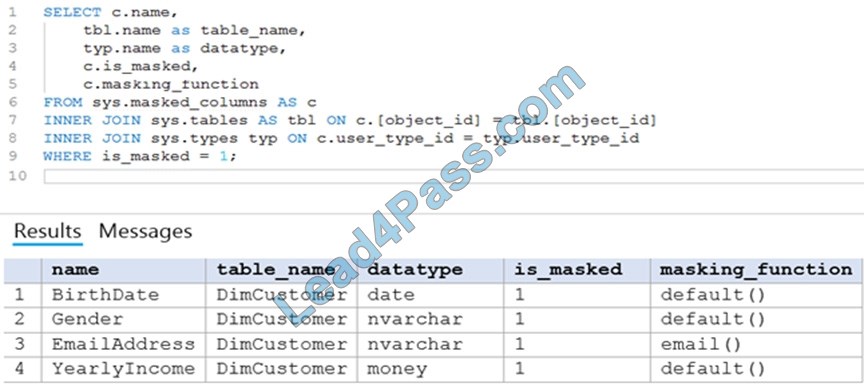
User1 is the only user who has access to the unmasked data.
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.
Hot Area:
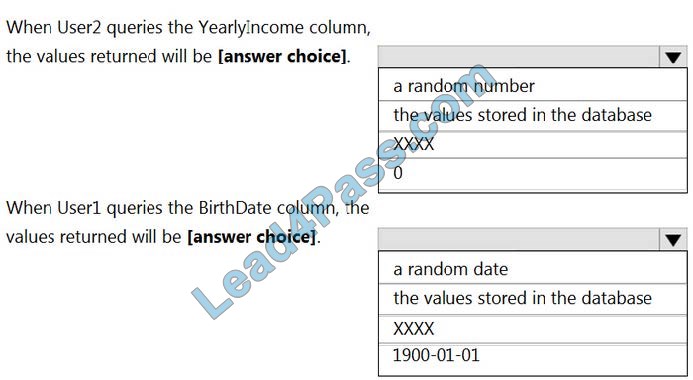
Correct Answer:
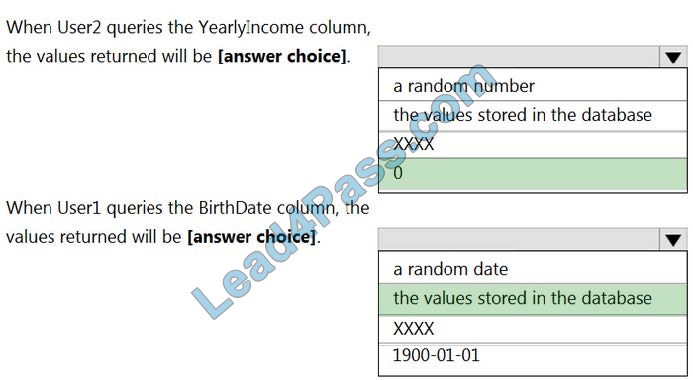
Box 1: 0
The YearlyIncome column is of the money data type.
The Default masking function: Full masking according to the data types of the designated fields
Use a zero value for numeric data types (bigint, bit, decimal, int, money, numeric, smallint, smallmoney, tinyint, float, real).
Box 2: the values stored in the database
Users with administrator privileges are always excluded from masking, and see the original data without any mask.
Reference:
https://docs.microsoft.com/en-us/azure/azure-sql/database/dynamic-data-masking-overview
Question 15:
You use Azure Data Lake Storage Gen2.
You need to ensure that workloads can use filter predicates and column projections to filter data at the time the data is read from the disk.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Reregister the Microsoft Data Lake Store resource provider.
B. Reregister the Azure Storage resource provider.
C. Create a storage policy that is scoped to a container.
D. Register the query acceleration feature.
E. Create a storage policy that is scoped to a container prefix filter.
Correct Answer: BD
…
Thank you for reading! I have told you how to successfully pass the Microsoft DP-203 exam.
You can choose DP-203 dumps: https://www.leads4pass.com/dp-203.html! Get the key to successfully pass the exam!
Wishing you happiness!